9割ポエムなサイトに唐突に現れる技術記事です。
完成図
とりあえず最終的に得たいもののイメージ。IPフィルターで破棄した通信の送信元国と回数、ポート番号をDashboardで表示しています。
 (詳しく見るとChinaにTaiwanが含まれててアツいですね)
(詳しく見るとChinaにTaiwanが含まれててアツいですね)
前提条件
以下の行程が終了していることを前提とします。適当にググるとやり方が載っているので、いい感じにしてください。
.
├── docker-compose.yaml
├── elasticsearch_data
└── pipeline
└── pipeline.conf
docker-compose.yamlの準備
なにかいろいろなサイトを参考にして作ったdocker-compse.yamlは以下のような感じ。とりあえずで volumes が相対パスになっているので、変えたい人はよしなに。 また、logstashのvolumesでマウントしている /var/log は、自分のRTXのログが /var/log/rtx1200.log という名前で出力されるようにしているからなので、もし違う人はそこも合わせてあげてください。
version: "3"
services:
elasticsearch:
image: elasticsearch:7.2.0
container_name: elasticsearch
environment:
discovery.type: single-node
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./elasticsearch_data:/usr/share/elasticsearch/data
logstash:
image: docker.elastic.co/logstash/logstash:7.0.1
container_name: logstash
volumes:
- ./pipeline:/usr/share/logstash/pipeline
- /var/log:/var/log
depends_on:
- elasticsearch
kibana:
image: kibana:7.2.0
container_name: kibana
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
ports:
- "5601:5601"
depends_on:
- elasticsearch
(どうでもいいですが、KubernetesでYAMLが推奨されている理由が「Write your configuration files using YAML rather than JSON. Though these formats can be used interchangeably in almost all scenarios, YAML tends to be more user-friendly. 」ですが、この滅茶苦茶読みにくい、ゴミみたいな形式がJSONよりユーザーフレンドリーとは思わないんですけどね・・・。)
logstashのpipeline.conf作成
Pipelineの流れはElastic社の概念図がわかりやすいです。
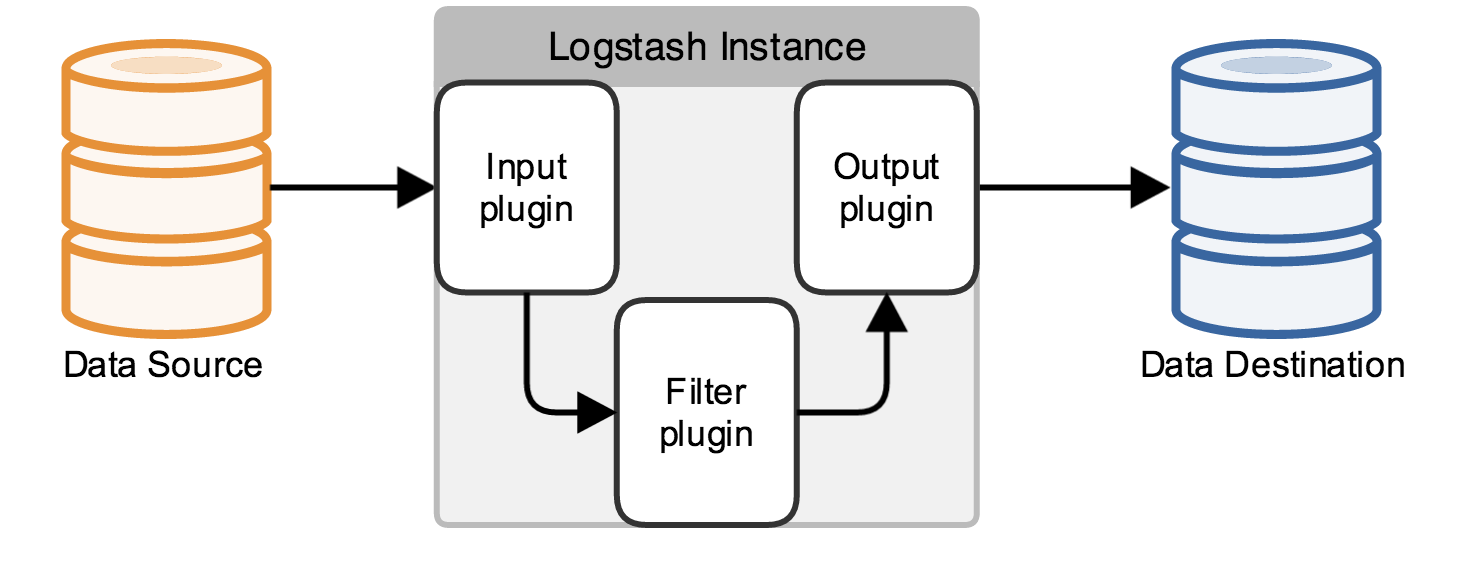
つまり、雑多なData Sourceからログを取得するために適切な方法をInput pluginで指定して、Filter pluginで整形、そのあとにOutput pluginでログを保存したいところに応じた保存方法を指定してあげるという流れ。その処理で適切なプラグインを指定して、プラグイン毎の設定をしてい\けばパイプラインの出来上がりというわけ。
今回の場合はsyslogでファイルとして取得できているRTX1200のログを読み込みたいので、Input pluginにfileプラグインを用います。細かい設定は公式ドキュメントに詳細が載っているので、そちらを参照。
今回はとりあえずという形なので、ファイルパス path と start_position のみを指定します。
pathは普通にsyslogが吐かれるファイルパスを指定すればOK。 start_position はlogstashがファイルのどこから読み込むかという設定になります。実運用時には前回取得時からの差分だけ、つまりファイル末尾だけを見たいので end を指定しますが、今回は古いデータをまとめて取得したいので beginning を指定します。
そんな流れでpipelineを書くと以下のような感じになります。
input {
file {
path => "/var/log/rtx1200.log"
start_position => "beginning"
}
}
これでRTX1200のログがlogstashのpiplineに乗るので、次は内容をどう整形するかを filer で指定します。今回は充実した正規表現リストが予め組み込まれている、お手軽プラグインのgrokを使って整形していきます。
grokプラグインで使用できる正規表現リストは以下を参照。ほとんどこれで良いんじゃないか?というレベル。
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patternsgithub.com
まず、syslogのヘッダー部を取り出します。つまりは、以下のようなsyslogの出力で言うところの日付とsyslogを発したホストIP、ログ内容のうち日付とホストのIPアドレスを抜き出す。
Aug 11 03:09:46 192.168.**.** [DHCPD] LAN1(port1) Allocates 192.168.**.**: **:**:**:**:**:** Aug 11 03:54:50 192.168.**.** PP[01] Rejected at IN(1012) filter: TCP **.**.**.**:**** > ***.***.***.***:*** Aug 11 03:54:51 192.168.12.1 PP[01] Rejected at IN(1012) filter: TCP **.**.**.**:**** > ***.***.***.***:***
grokを使って日付を time、ホストIPアドレスを hostname、ログ内容を messageというラベルをつけて抜き出すと以下のような感じになります。
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:time} %{IPV4:hostname} %{GREEDYDATA:message}" }
overwrite => [ "message" ]
}
ここでoverwriteを使って日付とホストIPを除いた、ログ本文をmessageラベルとして上書きしています。こうすることで、未処理のログ範囲を狭めていっています。
で、ここで細かくやっていくべきなのですが、いきなりドカンと一気に内容をパースしていきます。
- 定期実行処理のログ
- cronで定期実行されるログを取り出す。自分の場合はNTP同期のログ程度しか出力されないので、定期実行された内容程度を取り出すだけにしている。
- Inに対するIPフィルターで破棄された通信ログ
- Outに対するIPフィルターで破棄された通信ログ
- DHCP割当ログ
- ログイン履歴
- 残り
- 上記フィルターで該当したなかった雑多なログ
以上の項目をフィルターに設定すると、以下のような感じになります。
grok {
match => {
"message" => [
"\[SCHEDULE\] %{GREEDYDATA:schedule_what}",
"%{GREEDYDATA:in_rejected_interface} Rejected at IN\(%{NUMBER:in_rejected_filter_num:int}\) filter: %{WORD:in_rejected_protocol} %{IPV4:in_rejected_src_address}\:%{NUMBER:in_rejected_src_port:int} > %{IPV4:in_rejected_dst_address}\:%{NUMBER:in_rejected_dst_port:int}",
"%{GREEDYDATA:out_rejected_interface} Rejected at OUT\(%{NUMBER:out_filter_num:int}\) filter: %{WORD:out_rejected_protocol} %{IPV4:out_rejected_src_address}\:%{NUMBER:out_rejected_src_port:int} > %{IPV4:out_rejected_dst_address}\:%{NUMBER:out_rejected_dst_port:int}",
"\[DHCPD\] %{GREEDYDATA:dhcp_allocate_interface} Allocates %{IPV4:dhcp_allocate_address}: %{MAC:dhcp_allocate_mac_address}",
"%{GREEDYDATA:interface}: %{GREEDYDATA:interface_what} ",
"\'%{WORD:login_succeeded_user}\' succeeded for %{WORD:login_succeeded_protocol}: %{IPV4:login_succeeded_src_address}",
"%{GREEDYDATA:other_logs}"
]
}
}
ごちゃごちゃと書かれているけれども、基本的にはログ文中の取り出したい文字列部分を %{} で括り、中に該当する正規表現リストの名前とラベルを記載しているだけ。多少クセはあるが、ちょっとずつ書いていくとなんとなく慣れます。
なお、自分がハマったポイントだけ解説しておきます。ポート番号やIPフィルターの番号など、Int型が来るものに対して上記では %{NUMBER:hogehoge:int} としています。このようにしないと、Int型が文字列として扱われてしまい、Elasticsearch側で文字列として扱われて数値統計などができなくなってしまいます。
そして、今回の主目的である「フィルターに該当した通信の発信/送信元を地図にマッピングしたい」を実現するため、 geoip プラグインを用いてIPアドレスを地理情報に変換します。ここで、if でIPフィルターに該当して破棄された通信のIPアドレスがある場合のみにgeoipプラグインで地理情報に変換するようにしています。こうしないと、エラーが出力されてしまいます。
if [in_rejected_src_address]{
geoip {
source => "in_rejected_src_address"
target => "in_rejected_src_geo"
}
}
if [out_rejected_dst_address]{
geoip {
source => "out_rejected_dst_address"
target => "out_rejected_dst_geo"
}
}
そして最後にelasticsearchに記録するためoutputを指定します。今回はdocker-composeでelasticsearchを立ててよしなにするにで、以下のような非常にかんたんな記述になります。
output {
elasticsearch {
hosts => [ "http://elasticsearch:9200" ]
}
なお、Elasticsearchに直接突っ込まずにデバッグのために一旦ファイル出力したいなどの場合であれば以下のようにすればファイルに出力されます。
output {
file {
path => "/foo/bar/hogehoge.json"
}
}
以上をすべて繋げると、YAMAHA RTX1200のログをElasticsearchに突っ込むpipelineは以下のような感じになります。
input {
file {
path => "/var/log/rtx1200.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:time} %{IPV4:hostname} %{GREEDYDATA:message}" }
overwrite => [ "message" ]
}
grok {
match => {
"message" => [
"\[SCHEDULE\] %{GREEDYDATA:schedule_what}",
"%{GREEDYDATA:in_rejected_interface} Rejected at IN\(%{NUMBER:in_rejected_filter_num:int}\) filter: %{WORD:in_rejected_protocol} %{IPV4:in_rejected_src_address}\:%{NUMBER:in_rejected_src_port:int} > %{IPV4:in_rejected_dst_address}\:%{NUMBER:in_rejected_dst_port:int}",
"%{GREEDYDATA:out_rejected_interface} Rejected at OUT\(%{NUMBER:out_filter_num:int}\) filter: %{WORD:out_rejected_protocol} %{IPV4:out_rejected_src_address}\:%{NUMBER:out_rejected_src_port:int} > %{IPV4:out_rejected_dst_address}\:%{NUMBER:out_rejected_dst_port:int}",
"\[DHCPD\] %{GREEDYDATA:dhcp_allocate_interface} Allocates %{IPV4:dhcp_allocate_address}: %{MAC:dhcp_allocate_mac_address}",
"%{GREEDYDATA:interface}: %{GREEDYDATA:interface_what} ",
"\'%{WORD:login_succeeded_user}\' succeeded for %{WORD:login_succeeded_protocol}: %{IPV4:login_succeeded_src_address}",
"%{GREEDYDATA:other_logs}"
]
}
}
if [in_rejected_src_address]{
geoip {
source => "in_rejected_src_address"
target => "in_rejected_src_geo"
}
}
if [out_rejected_dst_address]{
geoip {
source => "out_rejected_dst_address"
target => "out_rejected_dst_geo"
}
}
}
output {
elasticsearch {
hosts => [ "http://elasticsearch:9200" ]
}
}
docker-compose up
以上で概ねの設定は終わったので、docker-compose.yamlがあるディレクトリで docker-compose up してElasticsearchその他を立ち上げましょう。
無事に立ち上がればdockerを動かしているマシンのIPアドレスの5601番でKibanaが立ち上がるはずです。結構、立ち上げに時間がかかります。
まだKibana側でElasticsearchのログを紐付けていないので、適当にサイドバーのDiscoverをクリックしてウィザードを立ち上げます。


適当にinedx patternにlogstashと打って、logstashで整形したログを登録します。

タイムスタンプを指定

登録終わり

実際にIPフィルターで破棄した通信を地図上にマッピングしていきます。Visualize→Create new visualizationでダイアログから Region Mapを選択、先程登録したlogstashのログを指定



遷移後、 サイドで Meric の Valueで Count を選択。その後、国毎に検出数をまとめたいので Buckets で Aggregation から Terms を選択し、 Filed からin_rejected_src_geo.continent_code.keyword を選択。

ここでデフォルト設定では直近15分のログからしか可視化をしないので、適当に上部からhoursではなくdaysに変更、UPDATE

そうすると、欲しかった地図マッピングが完成。

wrapup
最後あたり、凄まじく雑になりましたね。息切れです。そのうち、もうちょっとちゃんと書こう・・・。









 気持ちいい抱きまくら NV(ネイビー)")
 ふわふわ もちもち 28977-11")
![抱き枕 CMD9000 ハイクラス (160cm × 50cm) - COMODOオリジナル [日本製]](https://m.media-amazon.com/images/I/21J8Uu1Mu2L._SL500_.jpg "抱き枕 CMD9000 ハイクラス (160cm × 50cm) - COMODOオリジナル [日本製]")
DHR6000 ハイクラス")
DHR7000H プレミアム (160×50)")




